
IP Address Geolocation - How It Works, Why It Breaks, and What You Can Do About It
IP address geolocation underpins a wide range of Internet services: content localization, geo-restriction enforcement, fraud detection, CDN routing, and regulatory compliance all depend on mapping an IP address to a physical location. Yet the accuracy of these mappings is often poor, and the ecosystem for maintaining them is fragmented.
The Internet Architecture Board (IAB) convened a dedicated workshop on IP geolocation in December 2025. The resulting report confirms what many network operators have experienced firsthand: the signals are imperfect, adoption of self-reported mechanisms is uneven, and there’s meaningful room for improvement.
This post covers how IP geolocation works today, what the IAB workshop identified as the key gaps, and what operators can do about it, with a focus on geofeeds and two open-source projects I’ve built around them.
How IP Geolocation Works
The Basic Idea
When a server receives a connection from an IP address, it can query a geolocation database to retrieve a mapping of that address to a physical location, typically a country, region, and city. The consuming application then acts on that location: showing localized content, blocking access to geo-restricted material, or routing the request to the nearest server. Figure 1 shows this end-to-end flow.
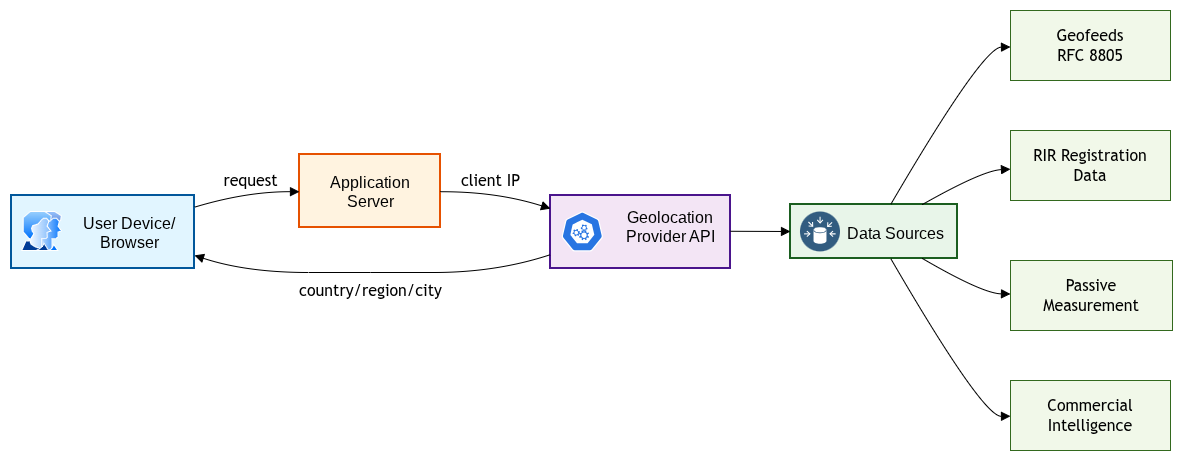
Where the Data Comes From
Geolocation databases are built from a mix of signals:
-
Geofeeds (RFC 8805): CSV-formatted files that network operators publish to declare the location of their IP prefixes. RFC 9632 defines how to discover and authenticate these feeds using the Routing Policy Specification Language (RPSL)
inetnum:class. - RIR registration data: IP address block assignments from regional internet registries (ARIN, RIPE, APNIC, LACNIC, AFRINIC) include address and contact information that can be used as a rough location signal.
- Passive measurement: Latency probes, traceroutes, and BGP topology data can infer location by triangulation.
- User-reported signals: Explicit location grants, GPS data, and Wi-Fi positioning can supplement IP-based guesses.
- Commercial intelligence: Geolocation providers layer in additional signals like reputation scores, VPN/proxy detection, and confidence ratings.
Most applications don’t consume geofeeds directly. Instead, they subscribe to a commercial geolocation provider (MaxMind, IPinfo, IP2Location, DB-IP) which aggregates all of these signals and exposes a simple lookup API.
The Core Assumption That Doesn’t Always Hold
The IAB workshop report highlights a fundamental architectural issue: current IP geolocation mechanisms generally assume a single, stable location is associated with an IP address. That assumption breaks in several common scenarios, illustrated in Figure 2:
- Cellular networks: IP addresses are assigned dynamically from pools and may be shared across a wide geographic area.
- Satellite networks: Starlink or Amazon Leo, for example, may use an IP address registered in one country while the user terminal is physically in another.
- NAT and CGNAT: Carrier-grade NAT means many users at different locations share a single public IP.
- Anycast: Cloud providers and CDNs advertise the same IP prefix from multiple locations globally. A geolocation database might map the prefix to a single city even though traffic is actually served from dozens of PoPs.
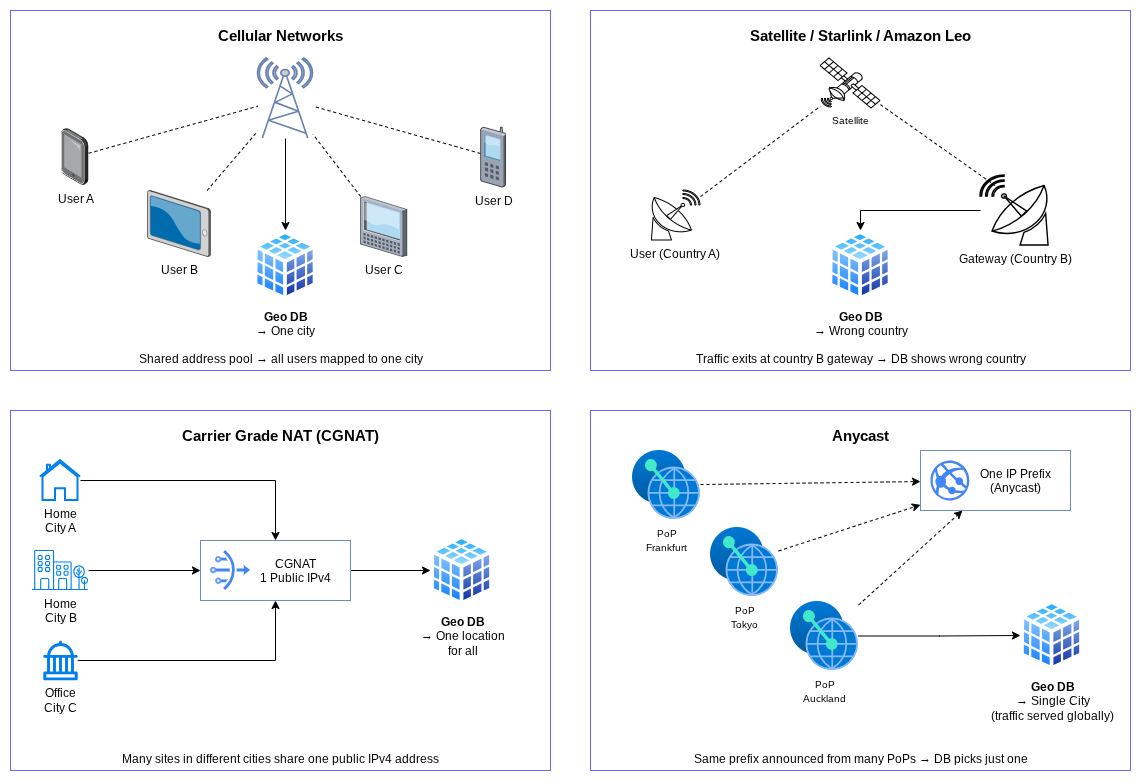
What the IAB Workshop Found
The IAB IP-GEO workshop, held December 3-5, 2025, gathered researchers, network operators, geolocation providers, and application developers to take stock of the state of IP geolocation. A few themes stood out.
Accuracy Gaps Are Widespread
Different providers don’t agree on mappings. Even when they do agree, that doesn’t guarantee accuracy. The workshop noted that confidence levels aren’t expressed in any standard format in geofeeds, so ambiguity is hidden from consumers.
Geofeeds Are Underutilized and Often Incomplete
Geofeeds are the primary self-reported mechanism for operators to influence how their IP space gets located. But adoption is uneven. Many operators, especially smaller ISPs, haven’t published geofeeds at all. For those that have, the data can be stale or inconsistent.
The Ecosystem Has Misaligned Incentives
Geolocation providers compete on accuracy but don’t have a clear mechanism to receive corrections from operators. Operators can publish geofeeds but have no guarantee that providers will consume them. Applications consume provider data but have no visibility into confidence or freshness. The workshop identified this as a structural ecosystem problem, not just a technical one.
Large Networks Are a Special Case
For major cloud providers like AWS, the geolocation challenge is particularly acute. AWS operates from dozens of regions and hundreds of edge locations worldwide, advertises addresses via anycast, and uses network border groups as the unit for IP prefix advertisement. The public ip-ranges.json file lists prefixes by region name, but that name is a logical identifier, not a precise geographic location.
Geofeeds: The Operator’s Tool
What Is a Geofeed?
A geofeed, as defined in RFC 8805, is a CSV file that a network operator publishes at a stable URL. Each row maps an IP prefix to a location using ISO 3166 country and subdivision codes, plus an optional city name:
# IANA-compliant geofeed
2001:db8::/32,US,US-VA,Ashburn,
203.0.113.0/24,DE,DE-HE,Frankfurt,
RFC 9632 additionally defines how to register the geofeed URL in RIR whois records and authenticate it with RPKI, so that consumers can discover and verify it without relying on out-of-band coordination. Figure 3 shows the full publication and discovery chain.
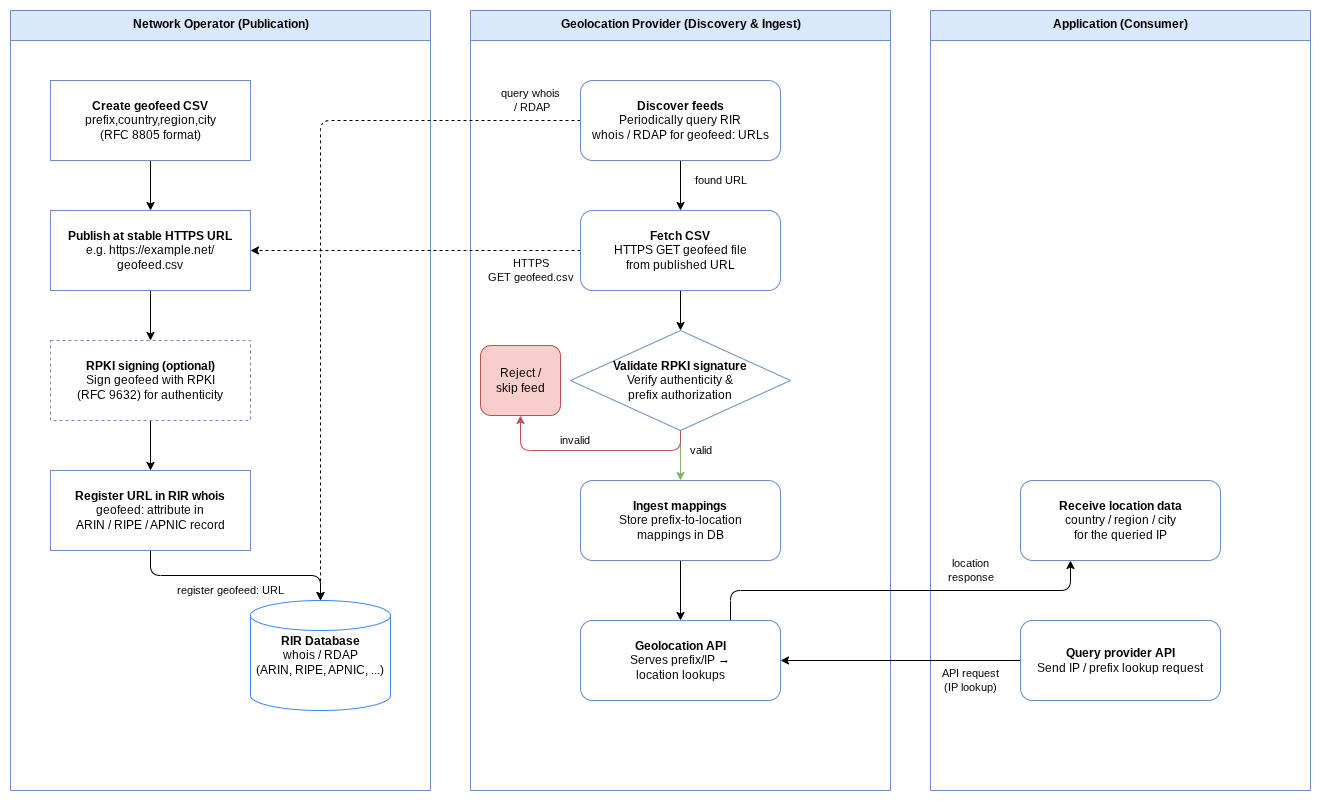
Geofeeds are the most direct lever network operators have over how their IP space gets located. Publishing an accurate geofeed doesn’t guarantee every provider will pick it up immediately, but it establishes the operator’s authoritative claim.
AWS Geolocation: A Specific Problem
AWS publishes its IP ranges via ip-ranges.json, which includes region identifiers like us-east-1 or ap-southeast-1. These identifiers don’t directly map to geographic coordinates. While some region names include a city hint (e.g., Europe (Frankfurt) maps to Frankfurt, Germany), others don’t: us-east-1 is “US East (N. Virginia)” but what city exactly? What subdivision?
Additionally, AWS’s own official geofeed (geo-ip-feed.csv) covers only a subset of prefixes and doesn’t include the finer-grained location detail that RFC 8805 supports.
Two Open-Source Projects
To help address the AWS geolocation gap, I’ve built two open-source tools.
AWS-Geofeed: Building a Detailed Geofeed for AS16509
The AWS-Geofeed project generates a complete, RFC 8805-compliant geofeed for AWS (AS16509) by ingesting the ip-ranges.json file and applying a manually curated location mapping.
The key challenge is converting AWS region identifiers into RFC 8805-compliant location tuples. For eu-central-1 (“Europe (Frankfurt)”), this is straightforward: DE,DE-HE,Frankfurt am Main,. For us-east-1 (“US East (N. Virginia)”), it requires additional research (AWS blog posts, job postings, publicly available network data) to pin down the specific locality. In this case that’s Ashburn, Virginia.
Mapping is done at the level of Network Border Groups, which are the units AWS uses to advertise IP addresses. Prefixes within a Network Border Group don’t move between groups, so the mapping stays stable even as AWS adds new prefixes.
Updates are triggered automatically via Amazon SNS when AWS makes changes to ip-ranges.json, keeping the geofeed current.
Geofeed-Monitor: Validating Geofeed Accuracy
Publishing a geofeed is only half the problem. The other half is knowing whether the location claims are actually accurate, and whether they’re being picked up by geolocation providers.
The Geofeed-Monitor project does exactly that. It monitors multiple geofeeds, including the official AWS feed, Google Cloud, Microsoft, Starlink, and the AWS-Geofeed above, and validates them across several dimensions:
- Cross-provider comparison: Fetches geofeed CSVs and compares the claimed location against MaxMind GeoLite2, IPinfo Lite, IP2Location Lite, and DB-IP to surface discrepancies.
- Location name validation: Checks each city against the GeoNames cities1000 dataset, with diacritic- and case-insensitive matching to handle alternate spellings (e.g. “München” / “Munich”).
- Routing visibility: Validates each prefix against RIPE RIS whois dumps to confirm it’s actually visible in the global routing table.
- RIR geofeed registration: Checks whether each prefix has a geofeed URL registered in RIR whois (per RFC 9092/9632) and compares it to the monitored feed URL.
- Alerting: Sends Slack alerts when locations are added or removed, accuracy drops, prefixes become unrouted, or embargo-listed countries appear in a feed.
- Change timestamps: Records when the RFC 8805 source was last modified and when each geolocation provider last updated its data for a given prefix. This makes it possible to measure how long providers take to incorporate a geofeed change, or whether they’re consuming geofeeds (RFC 8805 / RFC 9632) at all.
Live reports are published via GitHub Pages at https://chriselsen.github.io/Geofeed-Monitor/ and refreshed daily. Figure 4 shows an example of the per-feed summary landing page.
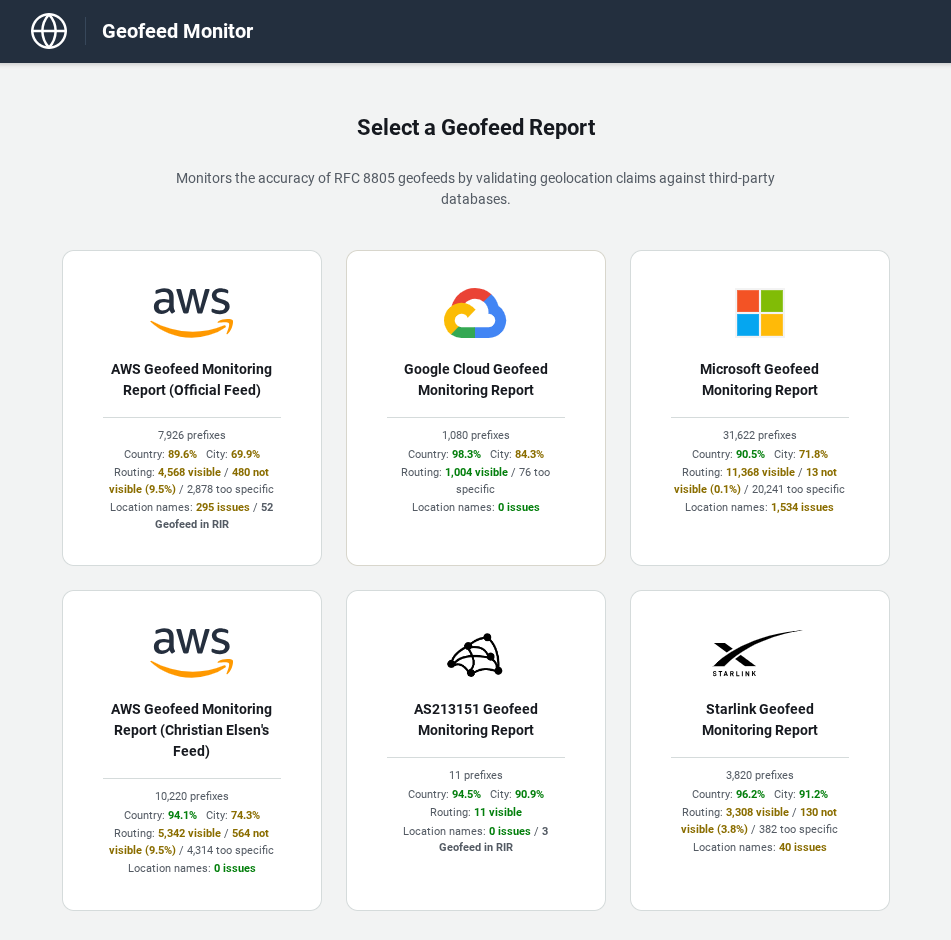
This kind of continuous monitoring matters for a few reasons. Geofeed data goes stale as AWS adds, changes, or retires prefixes. Geolocation providers update their databases on different schedules, so accuracy can drift. And the gap between what an operator claims and what providers actually serve to applications is rarely visible without explicit measurement.
Problems With UN/LOCODE as a Location Reference
RFC 8805 recommends using UN/LOCODE city names for the optional city field in geofeeds. In practice, we’ve found this creates several issues that make both geofeed creation and validation harder than they should be:
- Local names instead of English names: UN/LOCODE consistently uses local-language names for locations: “München” instead of “Munich”, “Warszawa” instead of “Warsaw”, “Köln” instead of “Cologne”. Most geolocation providers use English names in their databases. This mismatch makes mapping from a provider’s city name to an RFC 8805-compliant geofeed entry cumbersome, and makes validating a geofeed against provider data equally painful, since a string comparison will always fail for these cities.
- Missing locations: The UN/LOCODE database has notable gaps. For example, Zhongwei, a Chinese city with over 1 million inhabitants, is not included. When an operator needs to declare a prefix located in such a city, there is no compliant UN/LOCODE value to use.
- Typos revealing manual maintenance: Some geofeeds contain city names with obvious typos, for instance “Santaclara” instead of “Santa Clara”. Errors like these strongly suggest that the geofeed data is maintained manually rather than through an automated pipeline that would normalize names against a canonical source. If simple city names are misspelled, what confidence can we have in the prefix-to-location mappings themselves?
- Airport code misuse: Some operators appear to use airport codes as internal identifiers for locations, for example using “TPE” to represent Taipei, Taiwan. The problem arises when mapping these to UN/LOCODE regions: the airport’s actual location may differ from the city center. In the case of Taipei, Taiwan Taoyuan International Airport is in the city of Taoyuan, which is a different administrative region (Taoyuan City) than Taipei itself (Taipei City). When the geofeed uses the airport’s region rather than the city’s region, the resulting subdivision code is wrong.
- City-state confusion: For city-states and small countries like Bahrain, some geofeeds use the country name as the city name, listing “Bahrain” rather than specifying an actual city like Manama (the capital). While technically unambiguous for very small countries, this pattern is inconsistent with how UN/LOCODE works and breaks validation against city databases like GeoNames.
Note: These issues are not hypothetical. They were encountered while building the location validation in Geofeed-Monitor and directly affect the ability to cross-reference geofeed claims against geolocation provider data.
Why This Matters
Inaccurate IP geolocation has real consequences:
- Users in one country getting served content licensed for another
- Fraud detection systems flagging legitimate transactions based on wrong location data
- CDN traffic being routed to a suboptimal server because the anycast prefix is mapped to the wrong region
- Compliance systems making incorrect determinations about where data is being accessed from
The IAB workshop identified geofeeds as the most actionable near-term mechanism for improving accuracy. They’re simple to publish, open-standard, and give operators direct authorship over how their address space gets located. The gap is largely one of adoption and tooling.
If you operate IP address space, especially if you’re running cloud infrastructure, a CDN, or any kind of network with geographically distributed presence, publishing a well-maintained geofeed is one of the highest-leverage things you can do to improve the accuracy of the ecosystem.
Summary
IP geolocation is widely used but often inaccurate, with structural challenges the IAB’s December 2025 IP-GEO workshop laid out clearly. Geofeeds (RFC 8805, RFC 9632) are the operator-controlled mechanism for improving accuracy, though practical issues with UN/LOCODE as a location reference make compliant geofeed creation and validation harder than the standard suggests. For AWS specifically, the public ip-ranges.json file doesn’t provide the geographic detail that geolocation providers need. The AWS-Geofeed project fills that gap with an RFC-compliant, automatically updated feed, and Geofeed-Monitor provides ongoing validation against multiple providers and routing data.
Leave a comment